Introduction to NumPy and Pandas¶
Introduction¶
This notebook and accompanying webinar was developed and released by the enDAQ team. This is the second “chapter” of our series on Python for Mechanical Engineers:
Introduction to Numpy & Pandas
To sign up for future webinars and watch previous ones, visit our webinars page.
Recap of Python Introduction¶
Python is popular for good reason
There are many ways to interact with Python
Here we are in Google Colab based on Jupyter Notebooks
There are many open source libraries to use
Today we are covering two of the most popular:
Numpy
Pandas
And teasing a bit of:
Plotly
enDAQ

SO MANY Other Resources¶
Python is incredibly popular and so there are a lot of resources you can tap into online. You can either:
Just start coding and google specific questions when you get stuck (my preference for learning)
Follow a few online tutorials (like this first)
Do both!
Here are a few resources:
Jake VanderPlas Python Data Science Handbook
Buy the book for $35
Go through a series of well documented Colab Notebooks
Highly recommended resource!
Udemy Academy: Data Analysis with Pandas & NumPy in Python for Beginner



NumPy¶
NumPy provides an in depth overview of what exactly NumPy is. Quoting them: >At the core of the NumPy package, is the ndarray object. This encapsulates n-dimensional arrays of homogeneous data types, with many operations being performed in compiled code for performance.
Let’s get started by importing it, typically shortened to np because of how frequently it’s called. This will come standard in most Python distributions such as Anaconda. If you need to install it simply:
!pip install numpy
[ ]:
import numpy as np
Creating Arrays¶
Manually or from Lists¶
Manually create a list and demonstrate that operations on that list are difficult.
[ ]:
lst = [0, 1, 2, 3]
lst * 2
[0, 1, 2, 3, 0, 1, 2, 3]
That isn’t what we expected! For lists, we need to loop through all elements to apply a function to them which can be incredibly time consuming.
[ ]:
[i * 2 for i in lst]
[0, 2, 4, 6]
Now lets make a numpy array and once in an array, let’s show how intuitive operations are now that they are performed element by element.
[ ]:
array = np.array(lst)
print(array)
print(array * 2)
print(array + 2)
[0 1 2 3]
[0 2 4 6]
[2 3 4 5]
Let’s create a 2D matrix of 32 bit floats.
[ ]:
np.array([[1, 0, 0],
[0, 1, 0],
[0, 0, 1]], dtype=np.float32)
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]], dtype=float32)
Using Functions¶
We’ll go through a few here, but for more in depth examples and options see NumPy’s Array Creation Routines. These first few examples are for very basic arrays/matrices.
[ ]:
np.zeros(5)
array([0., 0., 0., 0., 0.])
[ ]:
np.zeros([2, 3])
array([[0., 0., 0.],
[0., 0., 0.]])
[ ]:
np.eye(3)
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
Now let’s start making sequences.
[ ]:
np.arange(10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
[ ]:
np.arange(0, #start
10) #stop (not included in array)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
[ ]:
np.arange(0, #start
10, #stop (not included in array)
2) #step size
array([0, 2, 4, 6, 8])
[ ]:
np.linspace(0, #start
10, #stop (default to be included, can pass in endpoint=False)
6) #number of data points evenly spaced
array([ 0., 2., 4., 6., 8., 10.])
[ ]:
np.logspace(0, #output starts being raised to this value
3, #ending raised value
4) #number of data points
array([ 1., 10., 100., 1000.])
Logspace is the equivalent of rasing a base by a linspaced array.
[ ]:
10 ** np.linspace(0,3,4)
array([ 1., 10., 100., 1000.])
[ ]:
np.logspace(0, 4, 5, base=2)
array([ 1., 2., 4., 8., 16.])
If you don’t want to have to do the mental math to know what exponent to raise the values to, you can use geomspace but this only helps for base of 10.
[ ]:
np.geomspace(1, 1000, 4)
array([ 1., 10., 100., 1000.])
Random numbers!
[ ]:
np.random.rand(5)
array([0.05057259, 0.19699801, 0.46727495, 0.67357217, 0.60387782])
[ ]:
np.random.rand(2, 3)
array([[0.76299702, 0.06301467, 0.92031266],
[0.42219446, 0.73721929, 0.39450975]])
Indexing¶
Let’s first create a simple array.
[ ]:
array = np.arange(1, 11, 1)
array
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Now index the first item.
[ ]:
array[0]
1
Index the last item.
[ ]:
array[-1]
10
Grab every 2nd item.
[ ]:
array[::2]
array([1, 3, 5, 7, 9])
Grab every second item starting at index of 1 (the second value)
[ ]:
array[1::2]
array([ 2, 4, 6, 8, 10])
Start from the second item, going to the 7th but skipping every other. (Our first time using the full array[start (inclusive): stop (exclusive): step] array ‘slicing’ notation)
[ ]:
array[1:6:2]
array([2, 4, 6])
Reverse the order.
[ ]:
array[::-1]
array([10, 9, 8, 7, 6, 5, 4, 3, 2, 1])
Boolean operations to index the array.
[ ]:
array[array < 5]
array([1, 2, 3, 4])
[ ]:
array[array * 2 < 5]
array([1, 2])
Integer list can also index arrays.
[ ]:
array[[1,3,5]]
array([2, 4, 6])
Now let’s create a slightly more complicated, 2 dimensional array.
[ ]:
array_2d = np.arange(10).reshape((2, 5))
array_2d
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
Indexing the second dimension.
[ ]:
array_2d[:, 1]
array([1, 6])
Any combination of these indexing methods works as well.
[ ]:
array_2d[[True, False], 1::2]
array([[1, 3]])
[ ]:
array_2d[1, [0,1,4]]
array([5, 6, 9])
Operations¶
[ ]:
array
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
[ ]:
array + 100
array([101, 102, 103, 104, 105, 106, 107, 108, 109, 110])
[ ]:
array * 2
array([ 2, 4, 6, 8, 10, 12, 14, 16, 18, 20])
To raise all the elements in an array to an exponent we have to use the notation ** not ^.
[ ]:
array ** 2
array([ 1, 4, 9, 16, 25, 36, 49, 64, 81, 100])
Use that shape to create a new array matching it to do operations with.
[ ]:
array2 = np.arange(array.shape[0]) * 5
array2
array([ 0, 5, 10, 15, 20, 25, 30, 35, 40, 45])
[ ]:
array2 + array
array([ 1, 7, 13, 19, 25, 31, 37, 43, 49, 55])
Stats of an Array¶
[ ]:
print(array)
print(array_2d)
[ 1 2 3 4 5 6 7 8 9 10]
[[0 1 2 3 4]
[5 6 7 8 9]]
[ ]:
print(array.shape)
print(array_2d.shape)
(10,)
(2, 5)
[ ]:
print(len(array))
print(len(array_2d))
10
2
[ ]:
print(array.max())
print(array_2d.max())
10
9
[ ]:
print(array.min())
print(array_2d.min())
1
0
[ ]:
array.std()
2.8722813232690143
[ ]:
array.cumsum()
array([ 1, 3, 6, 10, 15, 21, 28, 36, 45, 55])
[ ]:
array.cumprod()
array([ 1, 2, 6, 24, 120, 720, 5040,
40320, 362880, 3628800])
Constants¶
[ ]:
np.pi
3.141592653589793
[ ]:
np.e
2.718281828459045
[ ]:
np.inf
inf
Functions¶
[ ]:
np.sin(np.pi / 2)
1.0
[ ]:
np.cos(np.pi)
-1.0
[ ]:
np.log(np.e)
1.0
[ ]:
np.log10(100)
2.0
[ ]:
np.log2(64)
6.0
To demonstrate rounding, let’s first make a new array with decimals.
[ ]:
array = np.arange(4) / 3
print(array)
np.around(array, 2)
[0. 0.33333333 0.66666667 1. ]
array([0. , 0.33, 0.67, 1. ])
Looping vs Vectorization¶
As mentioned in the beginning, NumPy uses machine code with their ndarray objects which is what leads to the performance improvements. Let’s demonstrate this by constructing a simple sine wave.
[ ]:
fs = 500 #sampling rate in Hz
d_t = 1 / fs #time steps in seconds
n_step = 1000 #number of steps (there will be n_step+1 data points)
amp = 1 #amplitude of sine wave
f = 2 #frequency of sine wave
time = np.linspace(0, #start time
n_step * d_t, #end time
num=n_step + 1) #number of data points, one more than the steps to include an endpoint
time.shape
(1001,)
First we make a function to loop through each element and calculate the amplitude.
[ ]:
def sine_wave_with_loop(time, amp, f, phase=0):
length = time.shape[0]
wave = np.zeros(length)
for i in range(length-1):
wave[i] = np.sin(2 * np.pi * f * time[i] + phase * np.pi / 180)*amp
return wave
Now let’s time how quickly that executes for our time array of 1,001 data points.
[ ]:
%timeit sine_wave_with_loop(time, amp, f)
The slowest run took 7.52 times longer than the fastest. This could mean that an intermediate result is being cached.
100 loops, best of 5: 2.55 ms per loop
Now let’s do the same using NumPy’s sine function and vectorization.
[ ]:
def sine_wave_with_numpy(time, amp, f, phase=0):
"""Takes in a time array and sine wave parameters, returns an array of the sine wave amplitude."""
return np.sin(2 * np.pi * f * time + phase * np.pi / 180) * amp
Notice my docstrings!
[ ]:
help(sine_wave_with_numpy)
Help on function sine_wave_with_numpy in module __main__:
sine_wave_with_numpy(time, amp, f, phase=0)
Takes in a time array and sine wave parameters, returns an array of the sine wave amplitude.
[ ]:
%timeit sine_wave_with_numpy(time, amp, f)
The slowest run took 4.34 times longer than the fastest. This could mean that an intermediate result is being cached.
10000 loops, best of 5: 27.9 µs per loop
Using vectorization is about 100x faster! And this increases the longer the loops are.
Why Vectorization Works So Much Faster¶
The above example highlights that NumPy is much faster, but why? Because it is using compiled machine code under the hood for it’s operations.
Python has the Numba package which can be used to do this compilation which we will do to highlight just why NumPy is faster (and recommended!).
[ ]:
from numba import njit
numba_sine_wave_with_loop = njit(sine_wave_with_loop)
numba_sine_wave_with_numpy = njit(sine_wave_with_numpy)
[ ]:
%timeit numba_sine_wave_with_loop(time, amp, f)
%timeit numba_sine_wave_with_numpy(time, amp, f)
The slowest run took 14426.53 times longer than the fastest. This could mean that an intermediate result is being cached.
1 loop, best of 5: 22.8 µs per loop
The slowest run took 11783.25 times longer than the fastest. This could mean that an intermediate result is being cached.
1 loop, best of 5: 22.1 µs per loop
Let’s combine this into a DataFrame we’ll discuss next in more detail, but here’s a preview.
[ ]:
import pandas as pd
time_data = pd.DataFrame({'Time (us)':[2.77*100, 27.5, 23.1, 22.6],
'Method':['Loop','NumPy','Loop','NumPy'],
'Numba?':['w/o','w/o','w','w']}
)
time_data
| Time (us) | Method | Numba? | |
|---|---|---|---|
| 0 | 277.0 | Loop | w/o |
| 1 | 27.5 | NumPy | w/o |
| 2 | 23.1 | Loop | w |
| 3 | 22.6 | NumPy | w |
Now let’s plot it and preview Plotly!
[ ]:
!pip install --upgrade -q plotly
import plotly.express as px
import plotly.io as pio; pio.renderers.default = "iframe"
fig = px.bar(time_data,
x="Method",
y="Time (us)",
color="Numba?",
title="Compute Time of a Sine Wave for 1000 Elements",
barmode='group')
fig.show()
|████████████████████████████████| 23.9 MB 1.5 MB/s
Pandas¶
Pandas is built on top of NumPy meaning that the data is stored still as NumPy ndarray objects under the hood. But it exposes a much more intuitive labeling/indexing architecture and allows you to link arrays of different types (strings, floats, integers etc.) to one another.
To quote Jake VanderPlas: >At the very basic level, Pandas objects can be thought of as enhanced versions of NumPy structured arrays in which the rows and columns are identified with labels rather than simple integer indices.
To start, import pandas as pd, again this will come standard in virtually all Python distributions such as Anaconda. But to install is simply:
!pip install pandas
[ ]:
import pandas as pd
There are three types of Pandas objects, we’ll only focus on the first two:
Series – 1D labeled homogeneous array, size-immutable
Data Frames – 2D labeled, size-mutable tabular structure with heterogenic columns
Panel – 3D labeled size mutable array.
Creating a Series¶
First let’s create a few numpy arrays.
[ ]:
amplitude = sine_wave_with_numpy(time, amp, f, 180)
print(time)
print(amplitude)
[0. 0.002 0.004 ... 1.996 1.998 2. ]
[ 1.22464680e-16 -2.51300954e-02 -5.02443182e-02 ... 5.02443182e-02
2.51300954e-02 1.10218212e-15]
Now let’s see what a series looks like made from one of the arrays.
[ ]:
pd.Series(amplitude)
0 1.224647e-16
1 -2.513010e-02
2 -5.024432e-02
3 -7.532681e-02
4 -1.003617e-01
...
996 1.003617e-01
997 7.532681e-02
998 5.024432e-02
999 2.513010e-02
1000 1.102182e-15
Length: 1001, dtype: float64
This type of series has some value, but you really start to see it when you add in an index.
[ ]:
series = pd.Series(data=amplitude,
index=time,
name='Amplitude')
series
0.000 1.224647e-16
0.002 -2.513010e-02
0.004 -5.024432e-02
0.006 -7.532681e-02
0.008 -1.003617e-01
...
1.992 1.003617e-01
1.994 7.532681e-02
1.996 5.024432e-02
1.998 2.513010e-02
2.000 1.102182e-15
Name: Amplitude, Length: 1001, dtype: float64
Here’s where Pandas shines - indexing is much more intuitive (and inclusive) to specify based on labels, not those confusing integer locations. We’ll come back to this when we have the dataframe next too.
[ ]:
series[0: 0.01]
0.000 1.224647e-16
0.002 -2.513010e-02
0.004 -5.024432e-02
0.006 -7.532681e-02
0.008 -1.003617e-01
0.010 -1.253332e-01
Name: Amplitude, dtype: float64
Being able to plot quickly is also a plus!
[ ]:
series.plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f51188d8310>
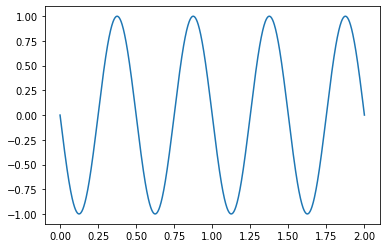
Remember we never left the NumPy array, it is still here and can be accessed with the following.
[ ]:
series.values
array([ 1.22464680e-16, -2.51300954e-02, -5.02443182e-02, ...,
5.02443182e-02, 2.51300954e-02, 1.10218212e-15])
[ ]:
series.to_numpy()
array([ 1.22464680e-16, -2.51300954e-02, -5.02443182e-02, ...,
5.02443182e-02, 2.51300954e-02, 1.10218212e-15])
Creating a DataFrame¶
A DataFrame is basically a sequence of aligned series objects, and by aligned I mean they share a common index or label. This let’s us mix and match types easily among other benefits.
First we’ll start creating dataframes using what is called a “dictionary” with keys and values.
[ ]:
df = pd.DataFrame({"Phase 0": sine_wave_with_numpy(time, amp, f, 00),
"Phase 90": sine_wave_with_numpy(time, amp, f, 90),
"Phase 180": sine_wave_with_numpy(time, amp, f, 180),
"Phase 270": sine_wave_with_numpy(time, amp, f, 270)},
index=time)
df
| Phase 0 | Phase 90 | Phase 180 | Phase 270 | |
|---|---|---|---|---|
| 0.000 | 0.000000e+00 | 1.000000 | 1.224647e-16 | -1.000000 |
| 0.002 | 2.513010e-02 | 0.999684 | -2.513010e-02 | -0.999684 |
| 0.004 | 5.024432e-02 | 0.998737 | -5.024432e-02 | -0.998737 |
| 0.006 | 7.532681e-02 | 0.997159 | -7.532681e-02 | -0.997159 |
| 0.008 | 1.003617e-01 | 0.994951 | -1.003617e-01 | -0.994951 |
| ... | ... | ... | ... | ... |
| 1.992 | -1.003617e-01 | 0.994951 | 1.003617e-01 | -0.994951 |
| 1.994 | -7.532681e-02 | 0.997159 | 7.532681e-02 | -0.997159 |
| 1.996 | -5.024432e-02 | 0.998737 | 5.024432e-02 | -0.998737 |
| 1.998 | -2.513010e-02 | 0.999684 | 2.513010e-02 | -0.999684 |
| 2.000 | -9.797174e-16 | 1.000000 | 1.102182e-15 | -1.000000 |
1001 rows × 4 columns
Plotting (Preview)¶
Dataframes also wrap around Matplotlib to allow for plotting directly from the dataframe object itself. This can also be done from the Pandas Series object too like we showed earlier.
[ ]:
df.plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f51187bd810>
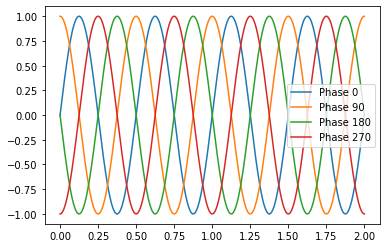
[ ]:
df['Max'] = df.max(axis=1)
df['Min'] = df.min(axis=1)
df
| Phase 0 | Phase 90 | Phase 180 | Phase 270 | Max | Min | |
|---|---|---|---|---|---|---|
| 0.000 | 0.000000e+00 | 1.000000 | 1.224647e-16 | -1.000000 | 1.000000 | -1.000000 |
| 0.002 | 2.513010e-02 | 0.999684 | -2.513010e-02 | -0.999684 | 0.999684 | -0.999684 |
| 0.004 | 5.024432e-02 | 0.998737 | -5.024432e-02 | -0.998737 | 0.998737 | -0.998737 |
| 0.006 | 7.532681e-02 | 0.997159 | -7.532681e-02 | -0.997159 | 0.997159 | -0.997159 |
| 0.008 | 1.003617e-01 | 0.994951 | -1.003617e-01 | -0.994951 | 0.994951 | -0.994951 |
| ... | ... | ... | ... | ... | ... | ... |
| 1.992 | -1.003617e-01 | 0.994951 | 1.003617e-01 | -0.994951 | 0.994951 | -0.994951 |
| 1.994 | -7.532681e-02 | 0.997159 | 7.532681e-02 | -0.997159 | 0.997159 | -0.997159 |
| 1.996 | -5.024432e-02 | 0.998737 | 5.024432e-02 | -0.998737 | 0.998737 | -0.998737 |
| 1.998 | -2.513010e-02 | 0.999684 | 2.513010e-02 | -0.999684 | 0.999684 | -0.999684 |
| 2.000 | -9.797174e-16 | 1.000000 | 1.102182e-15 | -1.000000 | 1.000000 | -1.000000 |
1001 rows × 6 columns
This will be the topic of the next webinar, plotting with Plotly!
Note that I need to install an upgraded version of Plotly in Colab because the default Plotly Express version doesn’t work in Colab (but their more advanced graph objects does).
[ ]:
!pip install --upgrade -q plotly
import plotly.express as px
[ ]:
px.line(df).show()
Load from CSV¶
This dataset was discussed in a blog on vibration metrics and used bearing data as an example.
Note you don’t have to use a CSV. They have a lot of other file formats natively supported (see full list):
hdf
feather
pickle
But I know everyone likes CSVs!
[ ]:
df = pd.read_csv('https://info.endaq.com/hubfs/Plots/bearing_data.csv', index_col=0)
df
| Fault_021 | Fault_014 | Fault_007 | Normal | |
|---|---|---|---|---|
| Time | ||||
| 0.000000 | -0.105351 | -0.074395 | 0.053116 | 0.046104 |
| 0.000083 | 0.132888 | 0.056365 | 0.116628 | -0.037134 |
| 0.000167 | -0.056535 | 0.201257 | 0.083654 | -0.089496 |
| 0.000250 | -0.193178 | -0.024528 | -0.026477 | -0.084906 |
| 0.000333 | 0.064879 | -0.072284 | 0.045319 | -0.038594 |
| ... | ... | ... | ... | ... |
| 9.999667 | 0.095754 | 0.145055 | -0.098923 | 0.064254 |
| 9.999750 | -0.123083 | 0.092263 | -0.067573 | 0.070721 |
| 9.999833 | -0.036508 | -0.168120 | 0.005685 | 0.103265 |
| 9.999917 | 0.097006 | -0.035898 | 0.093400 | 0.124335 |
| 10.000000 | -0.008762 | 0.165846 | 0.130923 | 0.114947 |
120000 rows × 4 columns
Save CSV¶
Like reading data, there are a host of native formats we can save data from a dataframe. See documentation.
[ ]:
df.to_csv('bearing-data.csv')
Simple Analysis¶
[ ]:
df.describe()
| Fault_021 | Fault_014 | Fault_007 | Normal | |
|---|---|---|---|---|
| count | 120000.000000 | 120000.000000 | 120000.000000 | 120000.000000 |
| mean | 0.012251 | 0.002729 | 0.002953 | 0.010755 |
| std | 0.198383 | 0.157761 | 0.121272 | 0.065060 |
| min | -1.037862 | -1.338628 | -0.650390 | -0.269114 |
| 25% | -0.107020 | -0.096649 | -0.072284 | -0.032544 |
| 50% | 0.011682 | 0.001299 | 0.004548 | 0.013351 |
| 75% | 0.132054 | 0.100872 | 0.080081 | 0.056535 |
| max | 0.917908 | 1.124376 | 0.594025 | 0.251382 |
[ ]:
df.std()
Fault_021 0.198383
Fault_014 0.157761
Fault_007 0.121272
Normal 0.065060
dtype: float64
[ ]:
df.max()
Fault_021 0.917908
Fault_014 1.124376
Fault_007 0.594025
Normal 0.251382
dtype: float64
Note that these built in Pandas functions are using NumPy to process and are the equivalent of doing the following.
[ ]:
np.max(df)
Fault_021 0.917908
Fault_014 1.124376
Fault_007 0.594025
Normal 0.251382
dtype: float64
[ ]:
df.quantile(0.25)
Fault_021 -0.107020
Fault_014 -0.096649
Fault_007 -0.072284
Normal -0.032544
Name: 0.25, dtype: float64
[ ]:
df['abs(max)'] = df.abs().max(axis=1)
df
| Fault_021 | Fault_014 | Fault_007 | Normal | abs(max) | |
|---|---|---|---|---|---|
| Time | |||||
| 0.000000 | -0.105351 | -0.074395 | 0.053116 | 0.046104 | 0.105351 |
| 0.000083 | 0.132888 | 0.056365 | 0.116628 | -0.037134 | 0.132888 |
| 0.000167 | -0.056535 | 0.201257 | 0.083654 | -0.089496 | 0.201257 |
| 0.000250 | -0.193178 | -0.024528 | -0.026477 | -0.084906 | 0.193178 |
| 0.000333 | 0.064879 | -0.072284 | 0.045319 | -0.038594 | 0.072284 |
| ... | ... | ... | ... | ... | ... |
| 9.999667 | 0.095754 | 0.145055 | -0.098923 | 0.064254 | 0.145055 |
| 9.999750 | -0.123083 | 0.092263 | -0.067573 | 0.070721 | 0.123083 |
| 9.999833 | -0.036508 | -0.168120 | 0.005685 | 0.103265 | 0.168120 |
| 9.999917 | 0.097006 | -0.035898 | 0.093400 | 0.124335 | 0.124335 |
| 10.000000 | -0.008762 | 0.165846 | 0.130923 | 0.114947 | 0.165846 |
120000 rows × 5 columns
Indexing¶
Here is where indexing in Python gets a whole lot more intuitive! A dataframe with an index let’s use index values (time in this case) to slice the dataframe, not rely on the nth element in the arrays.
[ ]:
df[0: 0.05]
| Fault_021 | Fault_014 | Fault_007 | Normal | abs(max) | |
|---|---|---|---|---|---|
| Time | |||||
| 0.000000 | -0.105351 | -0.074395 | 0.053116 | 0.046104 | 0.105351 |
| 0.000083 | 0.132888 | 0.056365 | 0.116628 | -0.037134 | 0.132888 |
| 0.000167 | -0.056535 | 0.201257 | 0.083654 | -0.089496 | 0.201257 |
| 0.000250 | -0.193178 | -0.024528 | -0.026477 | -0.084906 | 0.193178 |
| 0.000333 | 0.064879 | -0.072284 | 0.045319 | -0.038594 | 0.072284 |
| ... | ... | ... | ... | ... | ... |
| 0.049584 | 0.131010 | 0.129136 | -0.014619 | 0.021487 | 0.131010 |
| 0.049667 | 0.437675 | -0.221399 | -0.025340 | 0.021070 | 0.437675 |
| 0.049750 | 0.095754 | -0.120689 | 0.033137 | 0.035256 | 0.120689 |
| 0.049834 | -0.137269 | 0.275977 | 0.023716 | 0.044226 | 0.275977 |
| 0.049917 | 0.150203 | 0.019167 | -0.044670 | 0.005424 | 0.150203 |
600 rows × 5 columns
We can also use the same convention as before by adding in a step definition, in this case we’ll grab every 100th point.
[ ]:
df[0: 0.05: 100]
| Fault_021 | Fault_014 | Fault_007 | Normal | abs(max) | |
|---|---|---|---|---|---|
| Time | |||||
| 0.000000 | -0.105351 | -0.074395 | 0.053116 | 0.046104 | 0.105351 |
| 0.008333 | -0.481067 | -0.137745 | -0.010558 | -0.012934 | 0.481067 |
| 0.016667 | -0.265985 | -0.073746 | -0.140669 | 0.027329 | 0.265985 |
| 0.025000 | -0.192343 | 0.203856 | -0.168120 | -0.029832 | 0.203856 |
| 0.033334 | 0.018984 | 0.154476 | -0.072933 | 0.076353 | 0.154476 |
| 0.041667 | -0.289975 | -0.227409 | 0.088202 | 0.016898 | 0.289975 |
There are ways to use the integer based indexing if you so desire.
[ ]:
df.iloc[0:10]
| Fault_021 | Fault_014 | Fault_007 | Normal | abs(max) | |
|---|---|---|---|---|---|
| Time | |||||
| 0.000000 | -0.105351 | -0.074395 | 0.053116 | 0.046104 | 0.105351 |
| 0.000083 | 0.132888 | 0.056365 | 0.116628 | -0.037134 | 0.132888 |
| 0.000167 | -0.056535 | 0.201257 | 0.083654 | -0.089496 | 0.201257 |
| 0.000250 | -0.193178 | -0.024528 | -0.026477 | -0.084906 | 0.193178 |
| 0.000333 | 0.064879 | -0.072284 | 0.045319 | -0.038594 | 0.072284 |
| 0.000417 | 0.214874 | 0.034761 | 0.060751 | 0.025451 | 0.214874 |
| 0.000500 | -0.076353 | 0.094212 | -0.174130 | 0.040680 | 0.174130 |
| 0.000583 | -0.065922 | -0.070010 | -0.229521 | 0.042558 | 0.229521 |
| 0.000667 | 0.206529 | -0.079431 | 0.045482 | 0.038177 | 0.206529 |
| 0.000750 | 0.021487 | 0.092426 | 0.027452 | 0.044018 | 0.092426 |
Rolling¶
I love the rolling method which allows for easy rolling window calculations, something you’ll do frequently with time series data.
[ ]:
n = int(df.shape[0] / 100)
df.rolling(n).max()
| Fault_021 | Fault_014 | Fault_007 | Normal | abs(max) | |
|---|---|---|---|---|---|
| Time | |||||
| 0.000000 | NaN | NaN | NaN | NaN | NaN |
| 0.000083 | NaN | NaN | NaN | NaN | NaN |
| 0.000167 | NaN | NaN | NaN | NaN | NaN |
| 0.000250 | NaN | NaN | NaN | NaN | NaN |
| 0.000333 | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... |
| 9.999667 | 0.748721 | 0.768318 | 0.408362 | 0.18525 | 0.933137 |
| 9.999750 | 0.748721 | 0.768318 | 0.408362 | 0.18525 | 0.933137 |
| 9.999833 | 0.748721 | 0.768318 | 0.408362 | 0.18525 | 0.933137 |
| 9.999917 | 0.748721 | 0.768318 | 0.408362 | 0.18525 | 0.933137 |
| 10.000000 | 0.748721 | 0.768318 | 0.408362 | 0.18525 | 0.933137 |
120000 rows × 5 columns
[ ]:
df.rolling(n).max()[::n]
| Fault_021 | Fault_014 | Fault_007 | Normal | abs(max) | |
|---|---|---|---|---|---|
| Time | |||||
| 0.000000 | NaN | NaN | NaN | NaN | NaN |
| 0.100001 | 0.726190 | 0.710166 | 0.443448 | 0.184416 | 0.813809 |
| 0.200002 | 0.696150 | 0.641131 | 0.411773 | 0.204443 | 0.740376 |
| 0.300003 | 0.491289 | 0.846612 | 0.492178 | 0.172525 | 0.846612 |
| 0.400003 | 0.578699 | 0.608482 | 0.524828 | 0.204860 | 0.608482 |
| ... | ... | ... | ... | ... | ... |
| 9.500079 | 0.731823 | 0.500950 | 0.474798 | 0.206112 | 0.760820 |
| 9.600080 | 0.697818 | 0.713253 | 0.470412 | 0.190466 | 0.713253 |
| 9.700081 | 0.677791 | 0.547244 | 0.415996 | 0.229060 | 0.677791 |
| 9.800082 | 0.625220 | 0.569498 | 0.391469 | 0.176489 | 0.653801 |
| 9.900083 | 0.749555 | 0.949271 | 0.332342 | 0.176489 | 0.949271 |
100 rows × 5 columns
[ ]:
px.line(df.rolling(n).max()[::n]).show()
Datetime Data (Yay Finance!)¶
Let’s use Yahoo Finance and stock data as a relatable example of data with datetimes.
[ ]:
!pip install -q yfinance
import yfinance as yf
|████████████████████████████████| 6.3 MB 56.8 MB/s
Building wheel for yfinance (setup.py) ... done
[ ]:
df = yf.download(["SPY", "AAPL", "MSFT", "AMZN", "GOOGL"],
start='2019-01-01',
end='2021-09-24')
df
[*********************100%***********************] 5 of 5 completed
| Adj Close | Close | High | Low | Open | Volume | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AAPL | AMZN | GOOGL | MSFT | SPY | AAPL | AMZN | GOOGL | MSFT | SPY | AAPL | AMZN | GOOGL | MSFT | SPY | AAPL | AMZN | GOOGL | MSFT | SPY | AAPL | AMZN | GOOGL | MSFT | SPY | AAPL | AMZN | GOOGL | MSFT | SPY | |
| Date | ||||||||||||||||||||||||||||||
| 2019-01-02 | 38.382229 | 1539.130005 | 1054.680054 | 97.961319 | 238.694550 | 39.480000 | 1539.130005 | 1054.680054 | 101.120003 | 250.179993 | 39.712502 | 1553.359985 | 1060.790039 | 101.750000 | 251.210007 | 38.557499 | 1460.930054 | 1025.280029 | 98.940002 | 245.949997 | 38.722500 | 1465.199951 | 1027.199951 | 99.550003 | 245.979996 | 148158800 | 7983100 | 1593400 | 35329300 | 126925200 |
| 2019-01-03 | 34.559078 | 1500.280029 | 1025.469971 | 94.357529 | 232.998627 | 35.547501 | 1500.280029 | 1025.469971 | 97.400002 | 244.210007 | 36.430000 | 1538.000000 | 1066.260010 | 100.190002 | 248.570007 | 35.500000 | 1497.109985 | 1022.369995 | 97.199997 | 243.669998 | 35.994999 | 1520.010010 | 1050.670044 | 100.099998 | 248.229996 | 365248800 | 6975600 | 2098000 | 42579100 | 144140700 |
| 2019-01-04 | 36.034370 | 1575.390015 | 1078.069946 | 98.746010 | 240.803070 | 37.064999 | 1575.390015 | 1078.069946 | 101.930000 | 252.389999 | 37.137501 | 1594.000000 | 1080.000000 | 102.510002 | 253.110001 | 35.950001 | 1518.310059 | 1036.859985 | 98.930000 | 247.169998 | 36.132500 | 1530.000000 | 1042.560059 | 99.720001 | 247.589996 | 234428400 | 9182600 | 2301100 | 44060600 | 142628800 |
| 2019-01-07 | 35.954170 | 1629.510010 | 1075.920044 | 98.871956 | 242.701706 | 36.982498 | 1629.510010 | 1075.920044 | 102.059998 | 254.380005 | 37.207500 | 1634.560059 | 1082.699951 | 103.269997 | 255.949997 | 36.474998 | 1589.189941 | 1062.640015 | 100.980003 | 251.690002 | 37.174999 | 1602.310059 | 1080.969971 | 101.639999 | 252.690002 | 219111200 | 7993200 | 2372300 | 35656100 | 103139100 |
| 2019-01-08 | 36.639565 | 1656.579956 | 1085.369995 | 99.588829 | 244.981995 | 37.687500 | 1656.579956 | 1085.369995 | 102.800003 | 256.769989 | 37.955002 | 1676.609985 | 1093.349976 | 103.970001 | 257.309998 | 37.130001 | 1616.609985 | 1068.349976 | 101.709999 | 254.000000 | 37.389999 | 1664.689941 | 1086.000000 | 103.040001 | 256.820007 | 164101200 | 8881400 | 1770700 | 31514400 | 102512600 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2021-09-17 | 146.059998 | 3462.520020 | 2816.000000 | 299.869995 | 441.399994 | 146.059998 | 3462.520020 | 2816.000000 | 299.869995 | 441.399994 | 148.820007 | 3497.409912 | 2869.000000 | 304.500000 | 445.369995 | 145.759995 | 3452.129883 | 2809.399902 | 299.529999 | 441.019989 | 148.820007 | 3488.409912 | 2860.610107 | 304.170013 | 444.920013 | 129728700 | 4614100 | 2666800 | 41309300 | 118220200 |
| 2021-09-20 | 142.940002 | 3355.729980 | 2774.389893 | 294.299988 | 434.040009 | 142.940002 | 3355.729980 | 2774.389893 | 294.299988 | 434.040009 | 144.839996 | 3419.000000 | 2780.000000 | 298.720001 | 436.559998 | 141.270004 | 3305.010010 | 2726.439941 | 289.519989 | 428.859985 | 143.800003 | 3396.000000 | 2763.229980 | 296.329987 | 434.880005 | 123478900 | 4669100 | 2325900 | 38278700 | 166445500 |
| 2021-09-21 | 143.429993 | 3343.629883 | 2780.659912 | 294.799988 | 433.630005 | 143.429993 | 3343.629883 | 2780.659912 | 294.799988 | 433.630005 | 144.600006 | 3379.699951 | 2800.229980 | 297.540009 | 437.910004 | 142.779999 | 3332.389893 | 2765.560059 | 294.070007 | 433.070007 | 143.929993 | 3375.000000 | 2794.989990 | 295.690002 | 436.529999 | 75834000 | 2780900 | 1266600 | 22364100 | 92526100 |
| 2021-09-22 | 145.850006 | 3380.050049 | 2805.669922 | 298.579987 | 437.859985 | 145.850006 | 3380.050049 | 2805.669922 | 298.579987 | 437.859985 | 146.429993 | 3389.000000 | 2817.739990 | 300.220001 | 440.029999 | 143.699997 | 3341.050049 | 2771.030029 | 294.510010 | 433.750000 | 144.449997 | 3351.000000 | 2786.080078 | 296.730011 | 436.049988 | 76404300 | 2411400 | 1252800 | 26626300 | 102350100 |
| 2021-09-23 | 146.830002 | 3416.000000 | 2824.320068 | 299.559998 | 443.179993 | 146.830002 | 3416.000000 | 2824.320068 | 299.559998 | 443.179993 | 147.080002 | 3428.959961 | 2833.929932 | 300.899994 | 444.890015 | 145.639999 | 3380.050049 | 2808.030029 | 297.529999 | 439.600006 | 146.649994 | 3380.050049 | 2819.750000 | 298.850006 | 439.850006 | 64838200 | 2379400 | 1047600 | 18604600 | 76396000 |
688 rows × 30 columns
Let’s compare not the price, but the relative performance.
[ ]:
df = df['Adj Close']
df = df / df.iloc[0]
df
| AAPL | AMZN | GOOGL | MSFT | SPY | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-01-02 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| 2019-01-03 | 0.900393 | 0.974758 | 0.972304 | 0.963212 | 0.976137 |
| 2019-01-04 | 0.938830 | 1.023559 | 1.022177 | 1.008010 | 1.008834 |
| 2019-01-07 | 0.936740 | 1.058721 | 1.020139 | 1.009296 | 1.016788 |
| 2019-01-08 | 0.954597 | 1.076309 | 1.029099 | 1.016614 | 1.026341 |
| ... | ... | ... | ... | ... | ... |
| 2021-09-17 | 3.805407 | 2.249661 | 2.670004 | 3.061106 | 1.849225 |
| 2021-09-20 | 3.724119 | 2.180277 | 2.630551 | 3.004247 | 1.818391 |
| 2021-09-21 | 3.736885 | 2.172416 | 2.636496 | 3.009351 | 1.816673 |
| 2021-09-22 | 3.799936 | 2.196078 | 2.660210 | 3.047938 | 1.834395 |
| 2021-09-23 | 3.825468 | 2.219436 | 2.677893 | 3.057942 | 1.856682 |
688 rows × 5 columns
[ ]:
px.line(df).show()
The rolling function will play very nicely with datetime data as shown here when I get the moving average over a 40 day period. And this can handle unevenly sampled date easily.
[ ]:
px.line(df.rolling('40d').mean()).show()
Indexing with datetime data though will require a slightly extra step, but then it is easy.
[ ]:
from datetime import date
start = date(2021, 4, 1)
end = date(2021, 4, 30)
[ ]:
df[start:end]
| AAPL | AMZN | GOOGL | MSFT | SPY | |
|---|---|---|---|---|---|
| Date | |||||
| 2021-04-01 | 3.194388 | 2.053758 | 2.019361 | 2.463520 | 1.667522 |
| 2021-04-05 | 3.269703 | 2.096464 | 2.103918 | 2.531830 | 1.691456 |
| 2021-04-06 | 3.277754 | 2.094573 | 2.094721 | 2.519530 | 1.690457 |
| 2021-04-07 | 3.321644 | 2.130678 | 2.122947 | 2.540267 | 1.692414 |
| 2021-04-08 | 3.385532 | 2.143614 | 2.133756 | 2.574320 | 1.700447 |
| 2021-04-09 | 3.454094 | 2.190978 | 2.152947 | 2.600749 | 1.712810 |
| 2021-04-12 | 3.408386 | 2.195649 | 2.128247 | 2.601359 | 1.713434 |
| 2021-04-13 | 3.491232 | 2.209040 | 2.137549 | 2.627585 | 1.718512 |
| 2021-04-14 | 3.428903 | 2.165509 | 2.125678 | 2.598106 | 1.712644 |
| 2021-04-15 | 3.493050 | 2.195455 | 2.166771 | 2.637852 | 1.731041 |
| 2021-04-16 | 3.484220 | 2.208676 | 2.164400 | 2.650457 | 1.736827 |
| 2021-04-19 | 3.501880 | 2.190855 | 2.171047 | 2.630127 | 1.728294 |
| 2021-04-20 | 3.456951 | 2.166607 | 2.160854 | 2.625247 | 1.715640 |
| 2021-04-21 | 3.467079 | 2.184364 | 2.160229 | 2.648830 | 1.731874 |
| 2021-04-22 | 3.426566 | 2.149942 | 2.135738 | 2.614167 | 1.716057 |
| 2021-04-23 | 3.488376 | 2.170629 | 2.180690 | 2.654624 | 1.734663 |
| 2021-04-26 | 3.498764 | 2.214888 | 2.190171 | 2.658690 | 1.738284 |
| 2021-04-27 | 3.490193 | 2.220365 | 2.172204 | 2.662960 | 1.737910 |
| 2021-04-28 | 3.469157 | 2.247049 | 2.236735 | 2.587636 | 1.737410 |
| 2021-04-29 | 3.466560 | 2.255372 | 2.268707 | 2.566798 | 1.748482 |
| 2021-04-30 | 3.414100 | 2.252844 | 2.231482 | 2.563443 | 1.736994 |
[ ]:
pd.date_range(start='1/1/2019', end='08/31/2021', freq='M')
DatetimeIndex(['2019-01-31', '2019-02-28', '2019-03-31', '2019-04-30',
'2019-05-31', '2019-06-30', '2019-07-31', '2019-08-31',
'2019-09-30', '2019-10-31', '2019-11-30', '2019-12-31',
'2020-01-31', '2020-02-29', '2020-03-31', '2020-04-30',
'2020-05-31', '2020-06-30', '2020-07-31', '2020-08-31',
'2020-09-30', '2020-10-31', '2020-11-30', '2020-12-31',
'2021-01-31', '2021-02-28', '2021-03-31', '2021-04-30',
'2021-05-31', '2021-06-30', '2021-07-31', '2021-08-31'],
dtype='datetime64[ns]', freq='M')
[ ]:
df.resample(rule='Q').max()
| AAPL | AMZN | GOOGL | MSFT | SPY | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-03-31 | 1.240671 | 1.182005 | 1.172043 | 1.193962 | 1.143113 |
| 2019-06-30 | 1.346619 | 1.275045 | 1.228998 | 1.373424 | 1.187797 |
| 2019-09-30 | 1.435250 | 1.313073 | 1.181344 | 1.410902 | 1.218385 |
| 2019-12-31 | 1.887424 | 1.214842 | 1.291833 | 1.595237 | 1.315273 |
| 2020-03-31 | 2.108057 | 1.410030 | 1.445813 | 1.893692 | 1.377995 |
| 2020-06-30 | 2.367841 | 1.796086 | 1.388762 | 2.053599 | 1.324073 |
| 2020-09-30 | 3.473547 | 2.294446 | 1.628352 | 2.343208 | 1.471860 |
| 2020-12-31 | 3.544629 | 2.237387 | 1.730354 | 2.281494 | 1.551179 |
| 2021-03-31 | 3.712409 | 2.196046 | 2.008780 | 2.484634 | 1.649707 |
| 2021-06-30 | 3.562980 | 2.277546 | 2.323662 | 2.765187 | 1.787611 |
| 2021-09-30 | 4.082358 | 2.424363 | 2.753736 | 3.115720 | 1.892556 |
Sorting & Filtering on Tabular Data¶
To highlight filtering in DataFrames, we’ll use a dataset with a bunch of different columns/series of different types. This data was pulled directly from the enDAQ cloud API off some example recording files.
[ ]:
df = pd.read_csv('https://info.endaq.com/hubfs/data/endaq-cloud-table.csv')
df
| Unnamed: 0 | tags | id | serial_number_id | file_name | file_size | recording_length | recording_ts | created_ts | modified_ts | device | gpsLocationFull | velocityRMSFull | gpsSpeedFull | pressureMeanFull | samplePeakStartTime | displacementRMSFull | psuedoVelocityPeakFull | accelerationPeakFull | psdResultantOctave | samplePeakWindow | temperatureMeanFull | accelerometerSampleRateFull | psdPeakOctaves | microphonoeRMSFull | gyroscopeRMSFull | pvssResultantOctave | accelerationRMSFull | psdResultant1Hz | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | ['Vibration Severity: High', 'Shock Severity: ... | 6cd65b8f-1187-3bf9-a431-35304a7f84b7 | 9695 | train-passing-1632515146.ide | 10492602 | 73.612335 | 1588184436 | 1632515146 | 1632515146 | NaN | nan,nan | 6.969 | NaN | 104.620 | 1941.125 | 0.061 | 419.944 | 7.513 | [0. 0. 0.001 0.024 0.032 0.008 0.008 0.0... | [1.241 1.682 1.944 ... 1.852 1.372 1.473] | 23.432 | 19999.0 | [0. 0. 0.001 0.131 0.229 0.045 0.05 0.0... | NaN | 0.625 | [ 10.333 25.952 30.28 52.579 172.174 275.8... | 0.372 | [0. 0. 0. ... 0. 0. 0.] |
| 1 | 1 | ['Vibration Severity: Low', 'Acceleration Seve... | 342aacc3-cd91-3124-8cf4-0c7fece6dcab | 9316 | Seat-Top_09-1632515145.ide | 10491986 | 172.704559 | 1575800071 | 1632515146 | 1632515146 | NaN | nan,nan | 1.535 | NaN | 98.733 | 1265.964 | 0.040 | 86.595 | 1.105 | [0. 0. 0. 0. 0. 0. 0. 0. ... | [0.035 0.024 0.007 ... 0.067 0.031 0.022] | 20.133 | 3996.0 | [0. 0. 0.001 0. 0.001 0. 0.001 0.0... | NaN | 0.945 | [53.648 76.9 43.779 44.217 39.351 11.396 9.... | 0.082 | [ 0. 0. 0. ... nan nan nan] |
| 2 | 2 | ['Shock Severity: Very Low', 'Acceleration Sev... | 5c5592b4-2dbc-3124-be8f-c7179eecda49 | 10118 | Bolted-1632515144.ide | 6149229 | 29.396118 | 1619041447 | 1632515144 | 1632515144 | NaN | nan,nan | 14.101 | NaN | 99.652 | 17.445 | 0.154 | 148.276 | 15.343 | [0.001 0.003 0.004 0.064 0.106 0.102 0.103 0.1... | [5.283 5.944 5.19 ... 0.356 1.079 1.099] | 23.172 | 20000.0 | [0.001 0.004 0.004 0.128 0.125 0.119 0.14 0.1... | 25.507 | NaN | [ 26.338 27.636 64.097 102.733 107.863 124.6... | 2.398 | [0. 0.001 0.002 ... 0.002 0.001 0.001] |
| 3 | 3 | ['Shock Severity: Very Low', 'Acceleration Sev... | ef832e45-50fa-38b4-8f2c-91769f7cef6e | 10309 | RMI-2000-1632515143.ide | 5909632 | 60.250855 | 24 | 1632515143 | 1632515143 | NaN | nan,nan | 1.247 | NaN | 100.467 | 40.383 | 0.005 | 17.287 | 0.332 | [0. 0. 0. 0. 0.001 0.002 0.002 0.0... | [0.13 0.118 0.1 ... 0.105 0.1 0.066] | 21.806 | 4012.0 | [0. 0. 0. 0. 0.008 0.01 0.019 0.0... | 1.754 | 1.557 | [ 0.854 1.159 1.662 1.815 3.022 6.139 10.... | 0.079 | [ 0. 0. 0. ... nan nan nan] |
| 4 | 4 | ['Shock Severity: Very Low', 'Acceleration Sev... | 0396df6a-56b0-3e43-8e46-e1d0d7485ff5 | 9295 | Seat-Base_21-1632515142.ide | 5248836 | 83.092255 | 1575800210 | 1632515143 | 1632515143 | NaN | nan,nan | 7.318 | NaN | 98.930 | 1588.299 | 0.190 | 251.009 | 1.085 | [0.002 0.007 0.008 0.005 0.002 0.005 0.002 0.0... | [0.084 0.137 0.178 ... 0.347 0.324 0.286] | 17.820 | 4046.0 | [0.002 0.014 0.016 0.013 0.003 0.031 0.003 0.0... | NaN | 2.666 | [ 74.73 79.453 101.006 151.429 73.92 53.4... | 0.130 | [0.001 0.002 0.002 ... nan nan nan] |
| 5 | 5 | ['Drive-Test', 'Vibration Severity: Very Low',... | 5e293d65-c9e0-3aa1-9098-c9762e8fbc86 | 11046 | Drive-Home_01-1632515142.ide | 3632799 | 61.755371 | 1616178955 | 1632515142 | 1632515142 | NaN | nan,nan | 1.081 | NaN | 100.284 | 22.543 | 0.023 | 40.197 | 0.479 | [0. 0. 0. 0. 0.001 0. 0. 0. ... | [0.001 0.003 0.002 ... 0.011 0.008 0.006] | 29.061 | 4013.0 | [0. 0. 0. 0. 0.007 0. 0. 0. ... | 16.243 | 0.363 | [ 2.336 7.82 19.078 10.384 16.975 38.326 18.... | 0.021 | [ 0. 0. 0. ... nan nan nan] |
| 6 | 6 | ['Acceleration Severity: High', 'Shock Severit... | cd81c850-9e22-3b20-b570-7411e7a144cc | 0 | HiTest-Shock-1632515141.ide | 2655894 | 20.331848 | 1543936974 | 1632515141 | 1632515141 | NaN | nan,nan | 167.835 | NaN | 101.126 | 327.392 | 4.055 | 6058.093 | 619.178 | [0.304 0.486 0.399 0.454 0.347 0.178 0.185 0.1... | [ 3.088 3.019 2.893 ... 73.794 40.005 24.303] | 9.538 | 19997.0 | [ 0.304 0.537 0.479 0.811 0.624 0.554 0.... | NaN | NaN | [1378.444 2470.941 4368.78 5033.327 5814.49 ... | 11.645 | [0.157 0.304 0.42 ... 0.001 0.01 0.013] |
| 7 | 7 | ['Vibration Severity: High', 'Acceleration Sev... | 0931a23d-3515-3d11-bf97-bb9b2c7863be | 11162 | Calibration-Shake-1632515140.IDE | 2218130 | 27.882690 | 1621278970 | 1632515140 | 1632515140 | NaN | nan,nan | 46.346 | NaN | 102.251 | 8.460 | 0.617 | 1142.282 | 8.783 | [2.100e-02 7.400e-02 7.500e-02 4.900e-02 5.500... | [7.486 7.496 7.137 ... 7.997 8.294 7.806] | 24.545 | 5000.0 | [2.10000e-02 9.00000e-02 8.60000e-02 6.30000e-... | NaN | 0.166 | [ 90.703 198.651 288.078 183.492 126.417 108.4... | 2.712 | [0.007 0.021 0.055 ... nan nan nan] |
| 8 | 8 | ['Shock Severity: Very Low', 'Acceleration Sev... | c1571d10-2329-3aea-aa5d-223733f6336b | 10916 | FUSE_HSTAB_000005-1632515139.ide | 537562 | 18.491791 | 1619108004 | 1632515140 | 1632515140 | NaN | nan,nan | 1.504 | NaN | 90.706 | 12.519 | 0.036 | 53.375 | 0.202 | [ 0. 0. 0. 0. 0. 0. 0. nan nan nan nan n... | [0.001 0.001 0.001 ... 0.002 0.006 0.006] | 18.874 | 504.0 | [0. 0. 0.001 0.001 0. 0. 0. n... | NaN | 0.749 | [ 2.617 6.761 17.326 34.067 28.721 9.469 15.... | 0.011 | [ 0. 0. 0. ... nan nan nan] |
| 9 | 0 | ['Shock Severity: Medium', 'Acceleration Sever... | 8ce137ff-904e-314b-81ff-ff2cea279db2 | 9874 | Coffee_002-1631722736.IDE | 60959516 | 769.299896 | 952113744 | 1631722736 | 1631722736 | NaN | nan,nan | 5.606 | NaN | 100.339 | NaN | 0.104 | 1338.396 | 2.698 | [] | [] | 24.540 | 5000.0 | [] | NaN | 0.082 | [] | 0.059 | [] |
| 10 | 1 | ['Vibration Severity: High', 'Shock Severity: ... | 9d7383fb-40d6-34c1-9d0c-37f11c29bff5 | 11456 | 100_Joules_900_lbs-1629315313.ide | 1596714 | 20.200623 | 1627327315 | 1629315313 | 1629315313 | NaN | nan,nan | 53.875 | NaN | 98.751 | 5.643 | 1.053 | 2961.256 | 218.634 | [0.071 0.201 0.293 0.686 1.565 1.028 0.856 0.9... | [0.304 0.274 0.296 ... 1.513 1.313 0.652] | 24.180 | 5000.0 | [0.071 0.236 0.311 1.148 2.036 1.791 1.498 2.7... | NaN | 24.471 | [ 194.741 361.14 563.488 855.34 1712.229 ... | 2.877 | [0.02 0.071 0.138 ... nan nan nan] |
| 11 | 2 | ['Acceleration Severity: High', 'Shock Severit... | 5f35ed7f-ff55-36a3-896d-276f06a0e340 | 11456 | 50_Joules_900_lbs-1629315312.ide | 1597750 | 20.201752 | 1627329399 | 1629315312 | 1629315312 | NaN | nan,nan | 54.507 | NaN | 98.745 | 9.875 | 1.066 | 2907.650 | 231.212 | [0.074 0.196 0.327 0.874 1.521 0.917 0.478 0.7... | [0.304 0.21 0.098 ... 0.693 1.418 0.932] | 24.175 | 5000.0 | [0.074 0.232 0.392 1.258 2.045 2.049 1.143 2.3... | NaN | 15.575 | [ 242.141 388.517 736.981 1070.284 1843.722 ... | 2.423 | [0.021 0.074 0.137 ... nan nan nan] |
| 12 | 3 | ['Shock Severity: Very Low', 'Vibration Severi... | f7240576-47c6-34b8-bdce-3fe11bb5f1c6 | 11046 | Drive-Home_07-1626805222.ide | 36225758 | 634.732056 | 1616182557 | 1626805222 | 1626805222 | NaN | 42.4679965,-71.12926019999999 | 6.117 | 41.425 | 101.988 | NaN | 0.135 | 356.128 | 23.805 | [] | [] | 28.832 | 4012.0 | [] | 16.277 | 4.185 | [] | 0.097 | [] |
| 13 | 4 | ['Big-Mining'] | c2c234cc-8055-3fba-ad8b-446c4b6f85dc | 5120 | Mining-SSX28803_06-1626457584.IDE | 402920686 | 3238.119202 | 1536953304 | 1626457585 | 1626457585 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | [] | [] | NaN | NaN | [] | NaN | NaN | [] | NaN | [] |
| 14 | 5 | ['Shock Severity: Medium', 'Acceleration Sever... | 69fd99f8-3d85-38ec-9f5d-67e9d7b7e868 | 10030 | 200922_Moto_Max_Run5_Control_Larry-1626297441.ide | 4780893 | 99.325134 | 1600818455 | 1626297442 | 1626297442 | NaN | nan,nan | 55.569 | NaN | NaN | 62.573 | 1.060 | 1280.349 | 29.864 | [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] | [ 3.34 13.586 10.13 ... 7.737 8.978 8.672] | NaN | 4014.0 | [[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]\n [0... | NaN | NaN | [165.983 278.352 717.331 950.513 697.421 358.6... | 3.528 | [0.006 0.016 0.04 ... nan nan nan] |
| 15 | 6 | ['Ford'] | f38361de-30a7-3dda-aec4-e87a67d1ecbb | 9695 | ford_f150-1626296561.ide | 96097059 | 1207.678344 | 1584142508 | 1626296561 | 1626296561 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | [] | [] | NaN | NaN | [] | NaN | NaN | [] | NaN | [] |
| 16 | 7 | ['Shock Severity: High', 'Vibration Severity: ... | 40718e01-f422-3926-a22d-acf6daf1182b | 7530 | Motorcycle-Car-Crash-1626277852.ide | 10489262 | 151.069336 | 1562173372 | 1626277852 | 1626277852 | NaN | nan,nan | 143.437 | NaN | 100.363 | 1137.342 | 3.988 | 12831.590 | 480.737 | [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] | [3.371 3.641 3.649 ... 6.168 7.463 7.04 ] | 26.989 | 10001.0 | [[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]\n [0... | NaN | 19.810 | [ 2723.153 5977.212 11406.291 12031.397 7337... | 1.732 | [2.250e-01 8.390e-01 2.025e+00 ... 1.000e-03 1... |
| 17 | 8 | ['Shock Severity: Very Low', 'Surgical', 'Vibr... | ee6dc613-d422-347c-8119-f122a55ac81a | 11071 | surgical-instrument-1625829182.ide | 541994 | 6.951172 | 1619110390 | 1625829183 | 1625829183 | NaN | nan,nan | 24.418 | NaN | 99.879 | 4.020 | 0.242 | 387.312 | 5.739 | [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] | [0.667 0.549 1.05 ... 1.109 2.86 3.99 ] | 21.889 | 5000.0 | [[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]\n [0... | NaN | 4.647 | [ 88.953 171.73 104.303 71.184 58.883 72.4... | 1.568 | [0.001 0.001 0.003 ... nan nan nan] |
| 18 | 9 | ['Acceleration Severity: High', 'Shock Severit... | f642d81c-7fe7-37fd-ab75-d493fc0556db | 9680 | LOC__3__DAQ41551_11_01_02-1625170795.IDE | 2343292 | 28.456818 | 1616645179 | 1625170795 | 1625170795 | NaN | nan,nan | 372.049 | NaN | 105.682 | 2045.370 | 9.580 | 8907.949 | 622.040 | [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] | [ 32.679 24.925 30.95 ... 106.511 27.715 ... | 33.452 | 20010.0 | [[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]\n [0... | NaN | 286.217 | [2333.993 5629.021 6417.48 5802.895 3692.838 ... | 94.197 | [ 2.09 8.631 18.196 ... 69.565 59.225 60.801] |
| 19 | 10 | ['Vibration Severity: High', 'Shock Severity: ... | 0c0e92ae-214a-32bd-a5bb-5e1801da06b2 | 9680 | LOC__4__DAQ41551_15_05-1625170794.IDE | 6927958 | 64.486054 | 1616646130 | 1625170794 | 1625170794 | NaN | nan,nan | 148.591 | NaN | 105.750 | 3004.357 | 2.615 | 2153.020 | 585.863 | [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] | [14.223 14.903 24.949 ... 11.482 21.319 32.766] | 32.202 | 19992.0 | [[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]\n [0... | NaN | 277.654 | [ 378.188 748.336 1054.232 1115.369 756.905 ... | 46.528 | [ 0.072 0.302 0.816 ... 52.226 45.804 52.81 ] |
| 20 | 11 | ['Vibration Severity: High', 'Mining-Hammer', ... | 99ac47a8-63c2-38a4-8d92-508698eb3752 | 9680 | LOC__6__DAQ41551_25_01-1625170793.IDE | 8664238 | 63.878937 | 1616648007 | 1625170793 | 1625170793 | NaN | nan,nan | 145.223 | NaN | 102.875 | 4867.941 | 3.088 | 2357.599 | 564.966 | [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] | [ 66.83 54.723 63.536 ... 109.259 85.341 ... | 26.031 | 19992.0 | [[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]\n [0... | NaN | 245.929 | [ 780.577 1168.663 1851.417 1094.945 793.122 ... | 54.408 | [ 0.162 0.587 1.495 ... 45.639 43.86 40.177] |
| 21 | 12 | ['Mining-Hammer', 'Vibration Severity: High', ... | ebf31fb2-9d36-37de-999c-3edb01f17fb2 | 9680 | LOC__2__DAQ38060_06_03_05-1625170793.IDE | 1519172 | 27.057647 | 1616640862 | 1625170793 | 1625170793 | NaN | nan,nan | 323.287 | NaN | 104.473 | 1227.975 | 3.144 | 5845.241 | 995.670 | [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] | [ 33.294 29.392 19.99 ... 175.123 162.043 ... | 25.616 | 19998.0 | [[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]\n [0... | NaN | 266.815 | [1073.684 940.873 1063.151 957.568 975.826 ... | 131.087 | [ 0.371 0.409 0.787 ... 27.577 24.778 37.822] |
| 22 | 13 | ['Shock Severity: Very Low', 'Vibration Severi... | e39fe506-f39a-3301-866c-9da6a30f9577 | 9695 | Tilt_000000-1625156721.IDE | 719403 | 23.355163 | 1625156461 | 1625156722 | 1625156722 | NaN | nan,nan | 11.042 | NaN | 99.510 | 22.966 | 0.345 | 330.946 | 0.378 | [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] | [0.033 0.029 0.03 ... nan nan nan] | 26.410 | 5000.0 | [[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]\n [0... | NaN | 11.933 | [142.046 273.02 216.774 129.288 54.011 24.0... | 0.044 | [0.008 0.02 0.03 ... nan nan nan] |
[ ]:
df.columns
Index(['Unnamed: 0', 'tags', 'id', 'serial_number_id', 'file_name',
'file_size', 'recording_length', 'recording_ts', 'created_ts',
'modified_ts', 'device', 'gpsLocationFull', 'velocityRMSFull',
'gpsSpeedFull', 'pressureMeanFull', 'samplePeakStartTime',
'displacementRMSFull', 'psuedoVelocityPeakFull', 'accelerationPeakFull',
'psdResultantOctave', 'samplePeakWindow', 'temperatureMeanFull',
'accelerometerSampleRateFull', 'psdPeakOctaves', 'microphonoeRMSFull',
'gyroscopeRMSFull', 'pvssResultantOctave', 'accelerationRMSFull',
'psdResultant1Hz'],
dtype='object')
There’s a lot of data here! So we’ll focus on just a handful of columns and convert the time in seconds to a datetime object.
[ ]:
df = df[['serial_number_id', 'file_name', 'file_size', 'recording_length', 'recording_ts',
'accelerationPeakFull', 'psuedoVelocityPeakFull', 'accelerationRMSFull',
'velocityRMSFull', 'displacementRMSFull', 'pressureMeanFull', 'temperatureMeanFull']].copy()
df['recording_ts'] = pd.to_datetime(df['recording_ts'], unit='s')
df = df.sort_values(by=['recording_ts'], ascending=False)
df
| serial_number_id | file_name | file_size | recording_length | recording_ts | accelerationPeakFull | psuedoVelocityPeakFull | accelerationRMSFull | velocityRMSFull | displacementRMSFull | pressureMeanFull | temperatureMeanFull | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11 | 11456 | 50_Joules_900_lbs-1629315312.ide | 1597750 | 20.201752 | 2021-07-26 19:56:39 | 231.212 | 2907.650 | 2.423 | 54.507 | 1.066 | 98.745 | 24.175 |
| 10 | 11456 | 100_Joules_900_lbs-1629315313.ide | 1596714 | 20.200623 | 2021-07-26 19:21:55 | 218.634 | 2961.256 | 2.877 | 53.875 | 1.053 | 98.751 | 24.180 |
| 22 | 9695 | Tilt_000000-1625156721.IDE | 719403 | 23.355163 | 2021-07-01 16:21:01 | 0.378 | 330.946 | 0.044 | 11.042 | 0.345 | 99.510 | 26.410 |
| 7 | 11162 | Calibration-Shake-1632515140.IDE | 2218130 | 27.882690 | 2021-05-17 19:16:10 | 8.783 | 1142.282 | 2.712 | 46.346 | 0.617 | 102.251 | 24.545 |
| 17 | 11071 | surgical-instrument-1625829182.ide | 541994 | 6.951172 | 2021-04-22 16:53:10 | 5.739 | 387.312 | 1.568 | 24.418 | 0.242 | 99.879 | 21.889 |
| 8 | 10916 | FUSE_HSTAB_000005-1632515139.ide | 537562 | 18.491791 | 2021-04-22 16:13:24 | 0.202 | 53.375 | 0.011 | 1.504 | 0.036 | 90.706 | 18.874 |
| 2 | 10118 | Bolted-1632515144.ide | 6149229 | 29.396118 | 2021-04-21 21:44:07 | 15.343 | 148.276 | 2.398 | 14.101 | 0.154 | 99.652 | 23.172 |
| 20 | 9680 | LOC__6__DAQ41551_25_01-1625170793.IDE | 8664238 | 63.878937 | 2021-03-25 04:53:27 | 564.966 | 2357.599 | 54.408 | 145.223 | 3.088 | 102.875 | 26.031 |
| 19 | 9680 | LOC__4__DAQ41551_15_05-1625170794.IDE | 6927958 | 64.486054 | 2021-03-25 04:22:10 | 585.863 | 2153.020 | 46.528 | 148.591 | 2.615 | 105.750 | 32.202 |
| 18 | 9680 | LOC__3__DAQ41551_11_01_02-1625170795.IDE | 2343292 | 28.456818 | 2021-03-25 04:06:19 | 622.040 | 8907.949 | 94.197 | 372.049 | 9.580 | 105.682 | 33.452 |
| 21 | 9680 | LOC__2__DAQ38060_06_03_05-1625170793.IDE | 1519172 | 27.057647 | 2021-03-25 02:54:22 | 995.670 | 5845.241 | 131.087 | 323.287 | 3.144 | 104.473 | 25.616 |
| 12 | 11046 | Drive-Home_07-1626805222.ide | 36225758 | 634.732056 | 2021-03-19 19:35:57 | 23.805 | 356.128 | 0.097 | 6.117 | 0.135 | 101.988 | 28.832 |
| 5 | 11046 | Drive-Home_01-1632515142.ide | 3632799 | 61.755371 | 2021-03-19 18:35:55 | 0.479 | 40.197 | 0.021 | 1.081 | 0.023 | 100.284 | 29.061 |
| 14 | 10030 | 200922_Moto_Max_Run5_Control_Larry-1626297441.ide | 4780893 | 99.325134 | 2020-09-22 23:47:35 | 29.864 | 1280.349 | 3.528 | 55.569 | 1.060 | NaN | NaN |
| 0 | 9695 | train-passing-1632515146.ide | 10492602 | 73.612335 | 2020-04-29 18:20:36 | 7.513 | 419.944 | 0.372 | 6.969 | 0.061 | 104.620 | 23.432 |
| 15 | 9695 | ford_f150-1626296561.ide | 96097059 | 1207.678344 | 2020-03-13 23:35:08 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 9295 | Seat-Base_21-1632515142.ide | 5248836 | 83.092255 | 2019-12-08 10:16:50 | 1.085 | 251.009 | 0.130 | 7.318 | 0.190 | 98.930 | 17.820 |
| 1 | 9316 | Seat-Top_09-1632515145.ide | 10491986 | 172.704559 | 2019-12-08 10:14:31 | 1.105 | 86.595 | 0.082 | 1.535 | 0.040 | 98.733 | 20.133 |
| 16 | 7530 | Motorcycle-Car-Crash-1626277852.ide | 10489262 | 151.069336 | 2019-07-03 17:02:52 | 480.737 | 12831.590 | 1.732 | 143.437 | 3.988 | 100.363 | 26.989 |
| 6 | 0 | HiTest-Shock-1632515141.ide | 2655894 | 20.331848 | 2018-12-04 15:22:54 | 619.178 | 6058.093 | 11.645 | 167.835 | 4.055 | 101.126 | 9.538 |
| 13 | 5120 | Mining-SSX28803_06-1626457584.IDE | 402920686 | 3238.119202 | 2018-09-14 19:28:24 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 9 | 9874 | Coffee_002-1631722736.IDE | 60959516 | 769.299896 | 2000-03-03 20:02:24 | 2.698 | 1338.396 | 0.059 | 5.606 | 0.104 | 100.339 | 24.540 |
| 3 | 10309 | RMI-2000-1632515143.ide | 5909632 | 60.250855 | 1970-01-01 00:00:24 | 0.332 | 17.287 | 0.079 | 1.247 | 0.005 | 100.467 | 21.806 |
Filtering is made simple with boolean expressions that can be combined. There is also a method to sort_values by columns/series.
[ ]:
mask = df.recording_ts > pd.to_datetime('2021-01-01')
df[mask].sort_values(by=['serial_number_id'], ascending=False)
| serial_number_id | file_name | file_size | recording_length | recording_ts | accelerationPeakFull | psuedoVelocityPeakFull | accelerationRMSFull | velocityRMSFull | displacementRMSFull | pressureMeanFull | temperatureMeanFull | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11 | 11456 | 50_Joules_900_lbs-1629315312.ide | 1597750 | 20.201752 | 2021-07-26 19:56:39 | 231.212 | 2907.650 | 2.423 | 54.507 | 1.066 | 98.745 | 24.175 |
| 10 | 11456 | 100_Joules_900_lbs-1629315313.ide | 1596714 | 20.200623 | 2021-07-26 19:21:55 | 218.634 | 2961.256 | 2.877 | 53.875 | 1.053 | 98.751 | 24.180 |
| 7 | 11162 | Calibration-Shake-1632515140.IDE | 2218130 | 27.882690 | 2021-05-17 19:16:10 | 8.783 | 1142.282 | 2.712 | 46.346 | 0.617 | 102.251 | 24.545 |
| 17 | 11071 | surgical-instrument-1625829182.ide | 541994 | 6.951172 | 2021-04-22 16:53:10 | 5.739 | 387.312 | 1.568 | 24.418 | 0.242 | 99.879 | 21.889 |
| 12 | 11046 | Drive-Home_07-1626805222.ide | 36225758 | 634.732056 | 2021-03-19 19:35:57 | 23.805 | 356.128 | 0.097 | 6.117 | 0.135 | 101.988 | 28.832 |
| 5 | 11046 | Drive-Home_01-1632515142.ide | 3632799 | 61.755371 | 2021-03-19 18:35:55 | 0.479 | 40.197 | 0.021 | 1.081 | 0.023 | 100.284 | 29.061 |
| 8 | 10916 | FUSE_HSTAB_000005-1632515139.ide | 537562 | 18.491791 | 2021-04-22 16:13:24 | 0.202 | 53.375 | 0.011 | 1.504 | 0.036 | 90.706 | 18.874 |
| 2 | 10118 | Bolted-1632515144.ide | 6149229 | 29.396118 | 2021-04-21 21:44:07 | 15.343 | 148.276 | 2.398 | 14.101 | 0.154 | 99.652 | 23.172 |
| 22 | 9695 | Tilt_000000-1625156721.IDE | 719403 | 23.355163 | 2021-07-01 16:21:01 | 0.378 | 330.946 | 0.044 | 11.042 | 0.345 | 99.510 | 26.410 |
| 20 | 9680 | LOC__6__DAQ41551_25_01-1625170793.IDE | 8664238 | 63.878937 | 2021-03-25 04:53:27 | 564.966 | 2357.599 | 54.408 | 145.223 | 3.088 | 102.875 | 26.031 |
| 19 | 9680 | LOC__4__DAQ41551_15_05-1625170794.IDE | 6927958 | 64.486054 | 2021-03-25 04:22:10 | 585.863 | 2153.020 | 46.528 | 148.591 | 2.615 | 105.750 | 32.202 |
| 18 | 9680 | LOC__3__DAQ41551_11_01_02-1625170795.IDE | 2343292 | 28.456818 | 2021-03-25 04:06:19 | 622.040 | 8907.949 | 94.197 | 372.049 | 9.580 | 105.682 | 33.452 |
| 21 | 9680 | LOC__2__DAQ38060_06_03_05-1625170793.IDE | 1519172 | 27.057647 | 2021-03-25 02:54:22 | 995.670 | 5845.241 | 131.087 | 323.287 | 3.144 | 104.473 | 25.616 |
[ ]:
mask = (df.recording_ts > pd.to_datetime('2021-01-01')) & (df.accelerationPeakFull > 100)
df[mask].sort_values(by=['accelerationPeakFull'], ascending=False)
| serial_number_id | file_name | file_size | recording_length | recording_ts | accelerationPeakFull | psuedoVelocityPeakFull | accelerationRMSFull | velocityRMSFull | displacementRMSFull | pressureMeanFull | temperatureMeanFull | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 21 | 9680 | LOC__2__DAQ38060_06_03_05-1625170793.IDE | 1519172 | 27.057647 | 2021-03-25 02:54:22 | 995.670 | 5845.241 | 131.087 | 323.287 | 3.144 | 104.473 | 25.616 |
| 18 | 9680 | LOC__3__DAQ41551_11_01_02-1625170795.IDE | 2343292 | 28.456818 | 2021-03-25 04:06:19 | 622.040 | 8907.949 | 94.197 | 372.049 | 9.580 | 105.682 | 33.452 |
| 19 | 9680 | LOC__4__DAQ41551_15_05-1625170794.IDE | 6927958 | 64.486054 | 2021-03-25 04:22:10 | 585.863 | 2153.020 | 46.528 | 148.591 | 2.615 | 105.750 | 32.202 |
| 20 | 9680 | LOC__6__DAQ41551_25_01-1625170793.IDE | 8664238 | 63.878937 | 2021-03-25 04:53:27 | 564.966 | 2357.599 | 54.408 | 145.223 | 3.088 | 102.875 | 26.031 |
| 11 | 11456 | 50_Joules_900_lbs-1629315312.ide | 1597750 | 20.201752 | 2021-07-26 19:56:39 | 231.212 | 2907.650 | 2.423 | 54.507 | 1.066 | 98.745 | 24.175 |
| 10 | 11456 | 100_Joules_900_lbs-1629315313.ide | 1596714 | 20.200623 | 2021-07-26 19:21:55 | 218.634 | 2961.256 | 2.877 | 53.875 | 1.053 | 98.751 | 24.180 |
Another preview to plotly, but visualizing dataframes is made easy, even with mixed types.
[ ]:
px.scatter(df,
x="recording_ts",
y="accelerationRMSFull",
size="recording_length",
color="serial_number_id",
hover_name="file_name",
log_y=True,
size_max=60).show()
Plotly automatically made my colors a colorbar because I specified it based on a numeric value. If instead I change the type to string and replot, we’ll see discrete series for each device.
[ ]:
df['device'] = df["serial_number_id"].astype(str)
px.scatter(df,
x="recording_ts",
y="accelerationRMSFull",
size="recording_length",
color="device",
hover_name="file_name",
log_y=True,
size_max=60).show()
Preview of enDAQ Library¶
Installation¶
The code is live on GitHub, PyPI, and cleaner documentation is in process that will eventually live on a subdomain of endaq.com.
It can easily be installed with pip.
[ ]:
!pip install -q endaq
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
|████████████████████████████████| 92 kB 1.1 MB/s
|████████████████████████████████| 81 kB 11.1 MB/s
Building wheel for endaq (PEP 517) ... done
Building wheel for endaq-calc (PEP 517) ... done
Building wheel for endaq-cloud (PEP 517) ... done
Building wheel for endaq-ide (PEP 517) ... done
We are using newer versions of some of these libraries so we need to update them then reset the runtime.
[ ]:
! python -m pip install -U -q numpy scipy plotly pandas
exit()
|████████████████████████████████| 15.7 MB 417 kB/s
|████████████████████████████████| 28.5 MB 1.3 MB/s
|████████████████████████████████| 11.3 MB 28.8 MB/s
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
tensorflow 2.6.0 requires numpy~=1.19.2, but you have numpy 1.21.2 which is incompatible.
google-colab 1.0.0 requires pandas~=1.1.0; python_version >= "3.0", but you have pandas 1.3.3 which is incompatible.
datascience 0.10.6 requires folium==0.2.1, but you have folium 0.8.3 which is incompatible.
albumentations 0.1.12 requires imgaug<0.2.7,>=0.2.5, but you have imgaug 0.2.9 which is incompatible.
[ ]:
import numpy as np
import pandas as pd
import scipy
import plotly.express as px
import plotly.graph_objects as go
import endaq
Access Data from IDE¶
[ ]:
def get_doc_and_table(file_location, display_table=True, display_recorder_info=True):
"""Given an IDE file location, return the object and table summary"""
dataset = endaq.ide.get_doc(file_location, quiet=True)
table = endaq.ide.get_channel_table(dataset)
if display_recorder_info:
display(pd.Series(dataset.recorderInfo))
if display_table:
display(table)
return dataset, table.data
[ ]:
[doc,table] = get_doc_and_table('https://info.endaq.com/hubfs/data/Bolted.ide')
CalibrationDate 1583263964
CalibrationExpiry 1614799964
CalibrationSerialNumber 1999
RecorderTypeUID 1
RecorderSerial 10118
HwRev 1
FwRev 5
FwRevStr 2.0.36
ProductName W8-E100D40
PartNumber W8-E100D40
DateOfManufacture 1588954110
UniqueChipID 3782319969872279
McuType EFM32GG11B820F2048GL120
RecorderName Steve's Microphone
dtype: object
| channel | name | type | units | start | end | duration | samples | rate | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 8.0 | X (100g) | Acceleration | g | 00:00.0381 | 00:29.0667 | 00:29.0286 | 585728 | 19999.64 Hz |
| 1 | 8.1 | Y (100g) | Acceleration | g | 00:00.0381 | 00:29.0667 | 00:29.0286 | 585728 | 19999.64 Hz |
| 2 | 8.2 | Z (100g) | Acceleration | g | 00:00.0381 | 00:29.0667 | 00:29.0286 | 585728 | 19999.64 Hz |
| 3 | 8.3 | Mic | Audio | A | 00:00.0381 | 00:29.0667 | 00:29.0286 | 585728 | 19999.64 Hz |
| 4 | 80.0 | X (40g) | Acceleration | g | 00:00.0381 | 00:29.0669 | 00:29.0287 | 117760 | 4020.81 Hz |
| 5 | 80.1 | Y (40g) | Acceleration | g | 00:00.0381 | 00:29.0669 | 00:29.0287 | 117760 | 4020.81 Hz |
| 6 | 80.2 | Z (40g) | Acceleration | g | 00:00.0381 | 00:29.0669 | 00:29.0287 | 117760 | 4020.81 Hz |
| 7 | 36.0 | Pressure/Temperature:00 | Pressure | Pa | 00:00.0375 | 00:29.0771 | 00:29.0396 | 31 | 1.05 Hz |
| 8 | 36.1 | Pressure/Temperature:01 | Temperature | °C | 00:00.0375 | 00:29.0771 | 00:29.0396 | 31 | 1.05 Hz |
| 9 | 59.0 | Control Pad Pressure | Pressure | Pa | 00:00.0414 | 00:29.0489 | 00:29.0075 | 291 | 10.01 Hz |
| 10 | 59.1 | Control Pad Temperature | Temperature | °C | 00:00.0414 | 00:29.0489 | 00:29.0075 | 291 | 10.01 Hz |
| 11 | 59.2 | Relative Humidity | Relative Humidity | RH | 00:00.0414 | 00:29.0489 | 00:29.0075 | 291 | 10.01 Hz |
[ ]:
def get_primary_accel(dataset, table, preferred_ch=None, time_mode='seconds'):
"""Given an IDE object and summary table, return a dataframe of the accelerometer with the most samples unless a channel number is explicitely defined."""
if preferred_ch:
df = endaq.ide.to_pandas(doc.channels[preferred_ch],time_mode=time_mode)
else:
table = table.sort_values('samples',ascending=False)
channel = table.loc[table.type=='Acceleration','channel'].iloc[0].parent
df = endaq.ide.to_pandas(channel,time_mode=time_mode)
return df.drop(["Mic"], axis=1, errors="ignore")
[ ]:
df = get_primary_accel(doc, table)
df
| X (100g) | Y (100g) | Z (100g) | |
|---|---|---|---|
| timestamp | |||
| 0.381011 | -1.268025 | -2.824445 | -2.262913 |
| 0.381061 | -1.292439 | -1.902800 | -4.362554 |
| 0.381111 | -1.438926 | -1.164263 | -4.740978 |
| 0.381161 | -1.274128 | -0.914015 | -3.483635 |
| 0.381211 | -0.730907 | -1.115435 | -1.927214 |
| ... | ... | ... | ... |
| 29.667738 | -1.036088 | -1.817350 | -2.207980 |
| 29.667788 | -1.383993 | -1.585412 | -2.092012 |
| 29.667838 | -1.438926 | -1.933318 | -1.512169 |
| 29.667888 | -1.219196 | -2.738994 | -0.682078 |
| 29.667938 | -0.865187 | -3.526360 | 0.111391 |
585728 rows × 3 columns
PSD¶
We created a wrapper to SciPy’s Welch’s method to make the interface rely on dataframes.
[ ]:
df_psd = endaq.calc.psd.welch(df, bin_width=10)
fig = px.line(df_psd)
fig.update_layout(
title='Power Spectral Density',
xaxis_title="Frequency (Hz)",
yaxis_title="Acceleration (g^2/Hz)",
xaxis_type="log",
yaxis_type="log",
legend=dict(
orientation="h",
yanchor="top",
y=-.2,
xanchor="right",
x=1
)
)
fig.show()
We also provide a function to convert a linear spaced PSD to an octave spaced one.
[ ]:
df_psd_oct = endaq.calc.psd.to_octave(df_psd, fstart=4, octave_bins=3)
fig = px.line(df_psd_oct)
fig.update_layout(
title='Octave Spaced Power Spectral Density',
xaxis_title="Frequency (Hz)",
yaxis_title="Acceleration (g^2/Hz)",
xaxis_type="log",
yaxis_type="log",
legend=dict(
orientation="h",
yanchor="top",
y=-.2,
xanchor="right",
x=1
)
)
fig.show()
Shock¶
For some shock data, we’ll use the motorcycle crash test data discussed in our blog post on pseudo velocity.
[ ]:
[doc,table] = get_doc_and_table('https://info.endaq.com/hubfs/data/Motorcycle-Car-Crash.ide',
display_recorder_info=False,
display_table=False)
df = get_primary_accel(doc, table)
df
| X (500g) | Y (500g) | Z (500g) | |
|---|---|---|---|
| timestamp | |||
| 1024.088653 | 0.563998 | -5.142559 | 0.575260 |
| 1024.088753 | 0.409059 | -5.045741 | 0.847571 |
| 1024.088853 | 0.389691 | -5.142559 | 1.275489 |
| 1024.088953 | 0.234751 | -5.007014 | 0.905924 |
| 1024.089053 | 0.196017 | -5.181287 | 0.633613 |
| ... | ... | ... | ... |
| 1152.098232 | 0.796408 | -5.452379 | 0.497457 |
| 1152.098332 | 0.835142 | -5.607288 | 0.205695 |
| 1152.098432 | 1.048184 | -5.549197 | 0.205695 |
| 1152.098532 | 1.145022 | -5.936471 | 0.478006 |
| 1152.098632 | 1.280594 | -5.859016 | 0.419654 |
1280087 rows × 3 columns
Get Peak Time & Plot¶
[ ]:
def get_peak_time(df,num):
"""Get a subset of a dataframe around the peak value"""
peak_time = df.abs().max(axis=1).idxmax() #get the time at which the peak value occurs
d_t = (df.index[-1]-df.index[0])/(len(df.index)-1) #find the average time step
fs = 1/d_t #find the sampling rate
num = num / 2 #total number of datapoints to plot (divide by 2 because it will be two sided)
df_peak = df[peak_time - num / fs : peak_time + num / fs ] #segment the dataframe to be around that peak value
return df_peak
[ ]:
df_peak = get_peak_time(df,5000)
fig = px.line(df_peak)
fig.update_layout(
title="Time History around Peak",
xaxis_title="Time (s)",
yaxis_title="Acceleration (g)",
template="plotly_white",
legend=dict(
orientation="h",
yanchor="top",
y=-.2,
xanchor="right",
x=1
)
)
fig.show()
Filter & Plot¶
[ ]:
df_filtered = df - df.median() #For shock events it's sometimes best to avoid high pass filters because they can introduce weird artifacts
df_filtered = endaq.calc.filters.butterworth(df_filtered, low_cutoff=None, high_cutoff=150, half_order=3)
df_peak_filtered = get_peak_time(df_filtered,5000)
fig = px.line(df_peak_filtered)
fig.update_layout(
title="Filtered Time History around Peak",
xaxis_title="Time (s)",
yaxis_title="Acceleration (g)",
template="plotly_white",
legend=dict(
orientation="h",
yanchor="top",
y=-.2,
xanchor="right",
x=1
)
)
fig.show()
Integrate to Velocity & Displacement¶
[ ]:
[df_accel, df_vel, df_disp] = endaq.calc.integrate.integrals(df_peak_filtered, n=2, highpass_cutoff=None, tukey_percent=0)
df_vel = df_vel-df_vel.iloc[0] #forced the starting velocity to 0
df_vel = df_vel*9.81*39.37 #convert to in/s
[ ]:
fig = px.line(df_vel)
fig.update_layout(
title="Integrated Velocity Time History",
xaxis_title="Time (s)",
yaxis_title="Velocity (in/s)",
template="plotly_dark",
legend=dict(
orientation="h",
yanchor="top",
y=-.2,
xanchor="right",
x=1
)
)
fig.show()
Shock Response Spectrum¶
[ ]:
freqs=2 ** np.arange(0, 12, 1/12)
pvss = endaq.calc.shock.pseudo_velocity(df_peak-df_peak.median(), freqs=freqs, damp=0.05)
pvss = pvss*9.81*39.37 #convert to in/s
[ ]:
fig = px.line(pvss)
fig.update_layout(
title='Psuedo Velocity Shock Spectrum (PVSS)',
xaxis_title="Natural Frequency (Hz)",
yaxis_title="Psuedo Velocity (in/s)",
template="plotly_dark",
xaxis_type="log",
yaxis_type="log",
legend=dict(
orientation="h",
yanchor="top",
y=-.2,
xanchor="right",
x=1
)
)